

UPDATE 2014/02/01: Script is now version 1.2 to accommodate CS collations
Happy new year, everyone! With this post, I will be sharing a script I wrote to examine how many files you have for an instance, where they are, how big they are, and how full they are. It will also help you to reclaim some space, if that’s your goal. The script outputs 1 row per file.
DISCLAIMER: I am not advocating you shrink the free space out of your files. Generally, having free space is a good thing. Also, there are negative consequences of doing a file-shrink.
My advice
- Disable auto-shrink!
- Don’t use this, or any other mechanism, to otherwise routinely shrink files.
- Use it as the far exception, not the rule.
- Try to plan ahead, size your files, your drives, etc.
- Understand the side-effects of shrinking a file!
- This script will help give you information which will help you make a better decision.
- There may be non-technical factors that influence your decision on what to shrink or not shrink.
- Sometimes life happens… you may find that, in full awareness of the consequences, shrinking a file is the best option.
Perhaps I will blog about the effects of a fileshrink in a future post… Otherwise, there are many, many other posts on the matter. A quick web-search will get you started. I recommend Brent Ozar’s or Paul Randal’s, in particular. Bottom line: it’s really bad for performance; don’t do it unless you understand the costs and they are outweighed by the benefits. You’re the professional, and you’ll have to make that call, ultimately.
And that’s all I will say about that.
This script can also be used to snapshot space usage and trend it over time. There are a lot of things you probably want to remove if you’ll be doing that… but there’s a lot of useful data there.
Highlights of the Script
- Supports Filestream/FileTable, Database Snapshots
- Understands Filegroups
- Visual representation (careful, it is normalized)
- Generates convenient commands you can choose to run
- Displays VLF info
- Written for SQL 2012… works in 2008 with minor tweaks
- Converts sizes to human-readable format (but preserves raw bytes for sorting, filtering, etc)
Implementation
3 primary DMOs:
- sys.master_files
- I prefer this DMV… contains info for all DBs in one place
- Only way to get info for offline databases
- tempdb shows its initial size here, not its current size
- For user databases, I’ve seen times when this was inaccurate
- sys.database_files
- One view for each database
- Only way to get info for Filestream data
- sys.dm_io_virtual_file_stats
- DMF… can’t use CROSS APPLY prior to SQL 2012
- Only way to get true size, on disk, for database snapshots (NTFS sparse file)
Credit where Credit is Due
A big thanks to Ken Simmons and Tim Ford (cited at the bottom of this post) for their blog posts on the same topic. I derived many ideas and some coding techniques from their examples.
Output Sample

Additional columns:

And finally:

The entire result set can be found here:

The Script
/*
* Author: Ryan Snee
* Version: 1.2
* Date 20140201
* URL: http://sqlsnee.com/r/spaceused
*
* With inspiration from Tim Ford and Ken Simmons
* Tim's Original Script: http://www.mssqltips.com/sqlservertip/1629/determine-free-space-consumed-space-and-total-space-allocated-for-sql-server-databases/
* Ken's Original Script: http://www.mssqltips.com/sqlservertip/1510/script-to-determine-free-space-to-support-shrinking-sql-server-database-files/
*
* License: This work is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
* License Details: http://creativecommons.org/licenses/by-sa/3.0/deeD.en_US
*
* LIMITATIONS
* No support for Hekaton
* Modifications needed to work on SQL 2008 R2
*
* Does handle:
* Snapshots
* Filestream
* Filegroups
* Offline databases (partial support)
*
* Grabs Virtual Log File count
*
***************************
** Change History
**************************
** Version Date Author Description
** ------- -------- ------- --------------------------------------------------------------------------------------------------------------------
** 01.0 2013/12/27 Ryan v1 Published
** 01.1 2014/02/01 Ryan Fixed to work in a database with a CS collation
*
*/
SET NOCOUNT ON;
DECLARE
@LoopSafetyBefore int,
@LoopSafetyAfter int,
@sql nvarchar(max),
@dbName sysname,
@dbID int,
@PrintMsg varchar(100),
@Debug bit;
Set @Debug=0;
IF OBJECT_ID('tempdb..#DBs') IS NOT NULL
BEGIN
DROP TABLE #DBs
END
IF OBJECT_ID('tempdb..#FileGroup') IS NOT NULL
BEGIN
DROP TABLE #FileGroup
END
IF OBJECT_ID('tempdb..#TMPSPACEUSED') IS NOT NULL
BEGIN
DROP TABLE #TMPSPACEUSED
END
IF OBJECT_ID('tempdb..#LogInfo') IS NOT NULL
BEGIN
DROP TABLE #LogInfo
END
CREATE TABLE #TMPSPACEUSED (
database_id int
,DBNAME sysname
,SPACEUSED FLOAT
,size bigint
,data_space_id int
,FileID int
,[type] tinyint
,[type_desc] nvarchar(60)
,Name sysname
,physical_name nvarchar(260)
,growth bigint
,is_percent_growth bit
,[max_size] bigint
,is_read_only bit
,[VLFs] int NULL
);
CREATE TABLE #LogInfo(
RecoveryUnitID int,
FileId tinyint,
FileSize bigint,
StartOffset bigint,
FSeqNo int,
Status tinyint,
Parity tinyint,
CreateLSN numeric(25,0)
);
create table #DBs (id int primary key not null, dbname sysname, is_distributor bit, state tinyint, user_access tinyint, is_read_only bit, source_database_id int NULL, isDone bit default 0)
create table #FileGroup(id int identity(1,1) primary key not null, DatabaseID int not null, data_space_id int, name sysname, is_read_only bit)
INSERT INTO #DBs (id, dbname, is_distributor, state, user_access, is_read_only, source_database_id, isDone)
select sdb1.database_id, sdb1.name, sdb1.is_distributor, sdb1.state, sdb1.user_access, sdb1.is_read_only, sdb1.source_database_id, 0
from sys.databases sdb1
left join sys.databases sdb2
on sdb1.source_database_id=sdb2.database_id
where 1=1
AND sdb1.state=0 --Online
AND sdb1.user_access =0
AND sdb1.source_database_id is null OR (sdb2.state=0 and sdb2.user_access=0 )
WHILE EXISTS (SELECT dbname FROM #DBs WHERE isDone=0)
BEGIN
SET @dbName= NULL
SET @dbID= NULL
select @LoopSafetyBefore=count(*) FROM #DBs WHERE isDone=0;
--Do work here
select top 1 @dbName= dbname, @dbID=id from #DBs WHERE isDone=0 order by dbname
set @PrintMsg='--Scanning '+quotename(@dbName,']')
if(@Debug=1)
RAISERROR(@PrintMsg,0,0) WITH NOWAIT
SET @sql=nchar(9) + N'
USE '+QUOTENAME(@dbName)+';
INSERT INTO #FileGroup (DatabaseID, data_space_id, name, is_read_only)
select '+cast(@dbId as nvarchar(10))+', data_space_id, name, is_read_only from '+quotename(@dbName)+'.[sys].[filegroups];
INSERT INTO #TMPSPACEUSED ([database_id], [DBNAME], [SPACEUSED], [size], [data_space_id], [FileID], [type], [type_desc], [Name], [physical_name], [growth], [is_percent_growth], [max_size], [is_read_only])
Select '+cast(@dbID as varchar(50))+', '''+@DBName+''' as DBName, fileproperty(Name,''SpaceUsed'') SpaceUsed, size, data_space_id, file_ID, type, type_desc, Name, physical_name, growth, is_percent_growth, [max_size], is_read_only from '+quotename(@dbName)+'.[sys].[database_files]
TRUNCATE TABLE #LogInfo;
insert into #LogInfo
exec(''dbcc loginfo'');
update t
SET t.[VLFs]=
(select count(*) from #LogInfo LI
where LI.FileID=t.FileID and t.database_id='+cast(@dbID as varchar(50))+')
FROM #TMPSPACEUSED t
WHERE [t].[database_id]='+cast(@dbID as varchar(50))+'
'
if(@Debug=1)
print @sql
--Execute our statement
exec sp_executesql @sql;
UPDATE TOP (1) #DBs SET isDone=1 WHERE dbname=@dbName
select @LoopSafetyAfter =count(*) FROM #DBs WHERE isDone=0;
if(@LoopSafetyBefore<=@LoopSafetyAfter)
BEGIN
RAISERROR('Probable infinite Loop in databases',11,1) WITH NOWAIT
BREAK
END
END
;WITH a as(
SELECT
vs.volume_mount_point AS [Drive]
,vs.total_bytes as [DriveSize]
,cast((cast(vs.available_bytes as decimal(32,4))/(cast(vs.total_bytes as decimal(32,4))))*100 as decimal(18,2)) as [VolumePercentFree]
,vs.available_bytes as [DriveFreeBytes]
,DB.database_id,
[DB].NAME AS [Database],
[FG].name AS [FileGroup],
coalesce([D].NAME, [MF].[Name]) AS [LogicalFileName],
CASE [MF].[type]
WHEN 0 THEN 'DATA'
ELSE [MF].[type_desc]
END AS [FileType]
--master_files seems like inaccurate some times. Doesn't reflect true tempdb size, but rather its initial size
--database_files or io_virtual_file_stats seem best, in general. For Filestream, data_files is the only way.
--For snapshots, io_virtual_file_stats is the best way to get the true size, on disk
--master_files is the only option if the database is offline, in single_user mode, or otherwise unavailable
,CASE
WHEN [MF].[type] = 2 --FileStream
THEN ([D].size*8192)
WHEN DB.source_database_id is not null
THEN iovfs.size_on_disk_bytes
ELSE --Everything else
coalesce(iovfs.size_on_disk_bytes,(cast([MF].[size] as bigint)*8192))
END AS [FileSizeBytes]
,DB.source_database_id
,coalesce([D].[type], [MF].[type]) as [type]
,[D].[type_desc]
,CASE
WHEN (DB.source_database_id IS NOT NULL) OR ([D].[type]=2) THEN cast(0 as decimal(18,2))
ELSE CAST(([D].size-[D].spaceused)*8192 AS DECIMAL(18,2))
END AS [SpaceFree]
,CASE
WHEN (DB.source_database_id IS NOT NULL) THEN cast(iovfs.size_on_disk_bytes as decimal(18,2))
WHEN ([MF].[type]=2) THEN ([D].size*8192)
ELSE CAST(([D].spaceused)*8192 AS DECIMAL(18,2))
END AS [SpaceUsed]
,CASE
WHEN (DB.source_database_id IS NOT NULL) OR ([D].[type]=2) THEN cast(0 as decimal(18,2))
ELSE CAST(([D].size - D.SPACEUSED )*100.00/([D].size) AS decimal(9,2))
END AS [FilePercentFree]
,CASE
WHEN (DB.source_database_id IS NOT NULL) OR ([MF].[type]=2)
THEN 'N/A'
WHEN coalesce([D].is_percent_growth,[MF].[is_percent_growth]) =0
THEN CAST((coalesce([D].[growth], [MF].[growth]) *8/1024) AS VARCHAR(30))+' MB'
WHEN coalesce([D].is_percent_growth,[MF].[is_percent_growth]) =1
THEN CAST(coalesce([D].[growth], [MF].[growth]) AS VARCHAR(30))+'%'
END AS [GrowAt]
,CASE
WHEN DB.source_database_id IS NOT NULL --DB is a snapshot. Per BOL, use [D].SIZE to get max snapshot size
THEN (coalesce([D].[size], cast([MF].[size] as bigint))*8192)
WHEN ((coalesce([D].[max_size],[MF].[max_size])=0) AND ([D].[type]<>2)) --Autogrow is disabled. File is as big as it's going to get.
THEN coalesce(iovfs.size_on_disk_bytes,(cast([MF].[size] as bigint)*8192))
WHEN coalesce([D].[max_size],[MF].[max_size])=-1 --No limit
THEN NULL
WHEN coalesce([D].[max_size],[MF].[max_size])=268435456 --Max size possible in SQL Server
THEN NULL
ELSE
(coalesce([D].[max_size],[MF].[max_size])*8192)
END AS [MaxSizeBytes],
CASE
WHEN vs.available_bytes is null --We can't even get volume info for inaccessable databases
THEN null
WHEN ((DB.source_database_id IS NOT NULL) and ([D].[type]<> 2) and (([D].[size]*8192) > (vs.available_bytes + iovfs.size_on_disk_bytes))) --DB is a snapshot. Per BOL, use [D].SIZE to get max snapshot size. Here, we've over-provisioned. Number below will be negative.
THEN ((vs.available_bytes + iovfs.size_on_disk_bytes)-([D].[size]*8192))
WHEN ((DB.source_database_id IS NOT NULL) and ([D].[type]<> 2) and (([D].[size]*8192) <= (vs.available_bytes + iovfs.size_on_disk_bytes))) --DB is a snapshot. Per BOL, use [D].SIZE to get max snapshot size.
THEN (cast([D].[size] as bigint)*8192)
WHEN (([D].[max_size]=0) AND ([D].[type]<>2)) --Autogrow is disabled. File is as big as it's going to get.
THEN coalesce(iovfs.size_on_disk_bytes,(cast([MF].[size] as bigint)*8192))
WHEN (([D].[max_size])=-1 OR ([D].[max_size]=268435456)) --No limit/Max size possible in SQL Server
THEN
CASE
WHEN ([D].[type]=2) --When it's a filestream file, use database_files + availble bytes on the volume
THEN
(vs.available_bytes + ([D].size*8192))
ELSE
(vs.available_bytes + coalesce(iovfs.size_on_disk_bytes,(cast([MF].[size] as bigint)*8192)))
END
ELSE
CASE
WHEN (([D].[type]<> 2) and (([D].[max_size]*8192) > (vs.available_bytes + coalesce(iovfs.size_on_disk_bytes,(cast([MF].[size] as bigint)*8192))))) --Not Filestream and the max size > current size + freespace on the volume
THEN (vs.available_bytes + coalesce(iovfs.size_on_disk_bytes,(cast([MF].[size] as bigint)*8192)))
WHEN (([D].[type]=2) AND (([D].[max_size]*8192) > (vs.available_bytes + ([D].size*8192)))) --Filestream and the max size > current size + freespace on the volume
THEN vs.available_bytes + ([D].size*8192)
ELSE
([D].[max_size]*8192)
END
END AS [EffectiveMaxBytes],
[DB].recovery_model_desc AS [RecoveryModel],
coalesce([D].PHYSICAL_NAME, [MF].[Physical_Name]) AS [PhysicalName],
CASE
WHEN [DB].name='tempdb' THEN '--Don''t Shrink tempdb Online. It is known to cause corruption. Must start SQL in Single-User Mode.'
WHEN [DB].name='model' THEN '--Don''t shrink model'
WHEN [DB].name='master' THEN '--Don''t shrink master'
WHEN [DB].name='msdb' THEN '--Don''t shrink msdb'
WHEN [DB].[state]<>0 THEN '--Database is not ''Online'''
WHEN [DB].[is_read_only]=1 THEN '--Database is read_only and cannot be modified'
WHEN DB.source_database_id IS NOT NULL THEN '--Can''t shrink a snapshot'
WHEN [FG].[is_read_only]=1 THEN '--Filegroup is read-only'
WHEN [D].[type]=2 THEN 'use '+quotename([DB].[Name])+';'+char(13)+char(10)+'CHECKPOINT;'+char(13)+char(10)+'GO'+char(13)+char(10)+'sp_filestream_force_garbage_collection @dbname = '''+[DB].[Name]+''' , @filename = '''+[D].[Name]+''';'
ELSE
CASE
WHEN [D].type_desc='LOG' --If it's a log file, shrink it as much as possible
THEN 'USE ['+[DB].name+']; DBCC SHRINKFILE (N'''+[D].name+''' , 1);'
WHEN (max(cast([D].spaceused as bigint)) OVER(PARTITION BY [FG].name, DB.database_id, [D].[type]))>=[D].size --If the biggest amount of space used (out of all the files in the filegroup) is larger than our file is, we are not going to GROW the file
THEN '--Not going to grow our file'
ELSE 'USE ['+[DB].name+']; DBCC SHRINKFILE (N'''+[D].name+''' , '+cast(ceiling((max(cast([D].spaceused as bigint)) OVER(PARTITION BY [FG].name, DB.database_id, [D].[type]) * 8 / 1024.0)) as nvarchar(100))+');' --Otherwise, shrink all files in the filegroup to the greatest number of MB used (out of all the files in the filegroup)
END
END AS [ShrinkCmd],
CASE
WHEN [DB].name='tempdb' THEN '--Don''t change tempdb'
WHEN [DB].name='model' THEN '--Don''t change model'
WHEN [DB].name='master' THEN '--Don''t change master'
WHEN [DB].name='msdb' THEN '--Don''t change msdb'
WHEN [DB].name='dba_admin' THEN '--Don''t change dba_admin'
WHEN [DB].[state]<>0 THEN '--Database is not ''Online'''
WHEN DB.source_database_id IS NOT NULL THEN '--Can''t change a snapshot'
WHEN [D].[type]=2 THEN '--Filestream has no autogrow'
WHEN [DB].[is_read_only]=1 THEN '--Database is read_only and cannot be modified'
ELSE
CASE [D].type
WHEN 0
THEN
CASE
WHEN [D].growth=65536 AND [D].is_percent_growth=0
THEN ''
ELSE 'ALTER DATABASE ['+[DB].name+'] MODIFY FILE ( NAME = N'''+[D].name+''', FILEGROWTH = 524288KB )'
END
ELSE
CASE WHEN [D].growth=32768 AND [D].is_percent_growth=0
THEN ''
ELSE 'ALTER DATABASE ['+[DB].name+'] MODIFY FILE ( NAME = N'''+[D].name+''', FILEGROWTH = 262144KB )'
END
END
END AS [AutoGrowth]
,CASE
WHEN [DB].name='tempdb' THEN '--Don''t change tempdb'
WHEN [DB].name='model' THEN '--Don''t change model'
WHEN [DB].name='master' THEN '--Don''t change master'
WHEN [DB].name='msdb' THEN '--Don''t change msdb'
WHEN [DB].[state]<>0 THEN '--Database is not ''Online'''
WHEN DB.source_database_id IS NOT NULL THEN '--Can''t change a snapshot'
WHEN [DB].[is_read_only]=1 THEN '--Database is read_only and cannot be modified'
ELSE
CASE
WHEN ([DB].recovery_model=3 AND [D].FileID= min(D.FileID) OVER(PARTITION BY DB.database_id)) THEN 'ALTER DATABASE ['+[DB].name+'] SET RECOVERY FULL'
WHEN ([DB].recovery_model=1 AND [D].FileID= min(D.FileID) OVER(Partition BY DB.database_id)) THEN 'ALTER DATABASE ['+[DB].name+'] SET RECOVERY SIMPLE'
ELSE ''
END
END AS [RecoveryModelCmd]
,[DB].log_reuse_wait_desc
,CASE
WHEN [MF].[type]=1
THEN [D].[VLFs]
ELSE 0
END AS [VLFs]
,CASE
WHEN [DB].name='tempdb' THEN cast(0 as bigint)
WHEN [DB].name='model' THEN cast(0 as bigint)
WHEN [DB].name='master' THEN cast(0 as bigint)
WHEN [DB].name='msdb' THEN cast(0 as bigint)
WHEN DB.source_database_id IS NOT NULL THEN cast(0 as bigint)
WHEN [D].[type]=2 THEN cast(0 as bigint)
WHEN [DB].[is_read_only]=1 THEN cast(0 as bigint)
WHEN [DB].[state]<>0 THEN cast(0 as bigint)
WHEN [FG].[is_read_only]=1 THEN cast(0 as bigint)
ELSE
CASE
WHEN [D].type_desc='LOG' --If it's a log file, shrink it as much as possible
THEN [D].size-[D].spaceused --Not neccessarily, but a good guess
WHEN (max(cast([D].spaceused as bigint)) OVER(PARTITION BY [FG].name, DB.database_id, [D].[type]))>=[D].size --If the biggest amount of space used (out of all the files in the filegroup) is larger than our file is, we are not going to GROW the file
THEN 0
ELSE [D].size-(max(cast([D].spaceused as bigint)) OVER(PARTITION BY [FG].name, DB.database_id, [D].[type]))
END
END AS [ReclaimablePages]
FROM sys.databases [DB]
inner JOIN sys.master_files [MF]
ON [DB].database_id= [MF].database_id
left JOIN #TMPSPACEUSED D
ON [DB].database_id = D.database_id
AND [D].FileID = [MF].[file_id]
outer APPLY sys.dm_os_volume_stats([DB].database_id, [MF].[File_ID]) vs
left join #FileGroup FG
on [D].data_space_id=[FG].data_space_id
and DB.database_id=[FG].DatabaseID
outer apply sys.dm_io_virtual_file_stats([DB].database_id, [D].[FileID]) iovfs
), b as (
select
[a].[Drive] as [MountPoint]
,CASE
WHEN (a.DriveSize) > 1073741824000 THEN CAST(CAST(((a.DriveSize) / 1024.0/1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' TB'
WHEN (a.DriveSize) > 1048576000 THEN CAST(CAST(((a.DriveSize) / 1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' GB'
ELSE CAST(CAST(((a.DriveSize) / 1024.0/1024) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' MB'
END AS [DriveSize]
,CASE
WHEN ([a].[DriveFreeBytes]) > 1073741824000 THEN CAST(CAST((([a].[DriveFreeBytes]) / 1024.0/1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' TB'
WHEN ([a].[DriveFreeBytes]) > 1048576000 THEN CAST(CAST((([a].[DriveFreeBytes]) / 1024.0/1024/1024) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' GB'
ELSE CAST(CAST((([a].[DriveFreeBytes]) / 1024.0/1024) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' MB'
END AS [DriveFreeSpace]
,nchar(9621)+replicate(nchar(9608),floor((100-VolumePercentFree)/10))+replicate(nchar(9601),ceiling(VolumePercentFree/10))+nchar(9615) as [VolumePercentUsed]
,[a].[database_id] as [DatabaseID]
,[a].[Database] as [DatabaseName]
,CASE
WHEN (sum([a].[FileSizeBytes]) OVER(PARTITION BY [a].[database_id])) > 1073741824000 THEN CAST(cast((((sum([a].[FileSizeBytes]) OVER(PARTITION BY [a].[database_id])) /1024.0 /1024.0/1024.0/1024.0)) as decimal(18,2)) AS VARCHAR(20)) + ' TB'
WHEN (sum([a].[FileSizeBytes]) OVER(PARTITION BY [a].[database_id])) > 1048576000 THEN CAST(cast((((sum([a].[FileSizeBytes]) OVER(PARTITION BY [a].[database_id])) /1024.0/1024.0/1024.0)) as decimal(18,2)) AS VARCHAR(20)) + ' GB'
ELSE CAST(cast((((sum([a].[FileSizeBytes]) OVER(PARTITION BY [a].[database_id])) /1024.0 / 1024.0)) as decimal(18,2)) AS VARCHAR(20)) + ' MB'
END AS [DatabaseSize]
,[FileGroup] as [FileGroupName]
,[LogicalFileName]
,[FileType]
,CASE
WHEN ([a].[FileSizeBytes]) > 1073741824000 THEN CAST(CAST((([a].[FileSizeBytes]) / 1024.0/1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' TB'
WHEN ([a].[FileSizeBytes]) > 1048576000 THEN CAST(CAST((([a].[FileSizeBytes]) / 1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' GB'
ELSE CAST(CAST((([a].[FileSizeBytes]) / 1024.0/1024) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' MB'
END AS [FileSize]
,CASE WHEN (a.source_database_id IS NOT NULL) OR ([a].[type]=2) THEN 'N/A'
WHEN ([a].[SpaceFree]) > 1073741824000 THEN CAST(CAST((([a].[SpaceFree]) / 1024.0/1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' TB'
WHEN ([a].[SpaceFree]) > 1048576000 THEN CAST(CAST((([a].[SpaceFree]) / 1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' GB'
ELSE CAST(CAST((([a].[SpaceFree]) / 1024.0/1024) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' MB'
END as [SpaceFree]
,CASE
WHEN ([a].[SpaceUsed]) > 1073741824000 THEN CAST(CAST((([a].[SpaceUsed]) / 1024.0/1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' TB'
WHEN ([a].[SpaceUsed]) > 1048576000 THEN CAST(CAST((([a].[SpaceUsed]) / 1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' GB'
ELSE CAST(CAST((([a].[SpaceUsed]) / 1024.0/1024) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' MB'
END as [SpaceUsed]
,CASE WHEN (a.source_database_id IS NOT NULL) OR ([a].[type]=2) THEN 'N/A'
ELSE nchar(9621)+replicate(nchar(9608),floor((100-FilePercentFree)/10))+replicate(nchar(9601),ceiling(FilePercentFree/10))+nchar(9615)
END as [FilePercentUsed]
,[a].[GrowAt]
,CASE
WHEN ([a].[MaxSizeBytes]) > 1073741824000 THEN CAST(CAST((([a].[MaxSizeBytes]) / 1024.0/1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' TB'
WHEN ([a].[MaxSizeBytes]) > 1048576000 THEN CAST(CAST((([a].[MaxSizeBytes]) / 1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' GB'
ELSE CAST(CAST((([a].[MaxSizeBytes]) / 1024.0/1024) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' MB'
END as [MaxSize]
,CASE
WHEN ([a].[EffectiveMaxBytes]) > 1073741824000 THEN CAST(CAST((([a].[EffectiveMaxBytes]) / 1024.0/1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' TB'
WHEN ([a].[EffectiveMaxBytes]) > 1048576000 THEN CAST(CAST((([a].[EffectiveMaxBytes]) / 1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' GB'
ELSE CAST(CAST((([a].[EffectiveMaxBytes]) / 1024.0/1024) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' MB'
END as [EffectiveFileMax]
,nchar(9621)+replicate(nchar(9608),floor((CAST(100*((cast(a.SpaceUsed as decimal(18,2)))/(cast(a.EffectiveMaxBytes as decimal(18,2)))) AS decimal(18,2)))/10))+replicate(nchar(9601),ceiling((100-(CAST(100*((cast(a.SpaceUsed as decimal(18,2)))/(cast(a.EffectiveMaxBytes as decimal(18,2)))) AS decimal(18,2))))/10))+nchar(9615) as [UsedPercentOfEffectiveMax]
,CASE
WHEN ([a].[EffectiveMaxBytes]-[a].[SpaceUsed]) > 1073741824000 THEN CAST(CAST((([a].[EffectiveMaxBytes]-[a].[SpaceUsed]) / 1024.0/1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' TB'
WHEN ([a].[EffectiveMaxBytes]-[a].[SpaceUsed]) > 1048576000 THEN CAST(CAST((([a].[EffectiveMaxBytes]-[a].[SpaceUsed]) / 1024.0/1024.0/1024.0) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' GB'
ELSE CAST(CAST((([a].[EffectiveMaxBytes]-[a].[SpaceUsed]) / 1024.0/1024) AS DECIMAL(18,2)) AS VARCHAR(20)) + ' MB'
END as [AvailableSpaceToUse]
,[a].[PhysicalName]
,[a].[ShrinkCmd]
,[a].[AutoGrowth]
,[a].[RecoveryModel]
,[a].[RecoveryModelCmd]
,CASE
WHEN [a].[type]=1
THEN [a].[log_reuse_wait_desc]
ELSE ''
END AS [LogReuseWait]
,CASE
WHEN (([a].[type]=1) and ([a].[VLFs] is not null))
THEN cast([a].[VLFs] as varchar(50))
WHEN (([a].[type]=1) and ([a].[VLFs] is null))
THEN 'unknown'
ELSE ''
END AS [VLFCount]
,sum(ReclaimablePages) OVER(PARTITION BY a.database_id, a.FileGroup) as [ReclaimableInTheFilegroup]
--Raw data
,a.DriveSize as [drive_size]
,[a].[DriveFreeBytes] as [drive_free_bytes]
,sum([a].[FileSizeBytes]) OVER(PARTITION BY [a].[database_id]) as [db_size]
,[a].[FileSizeBytes] as [file_size_bytes]
,CASE
WHEN (a.source_database_id IS NOT NULL) OR ([a].[type]=2) THEN NULL
ELSE a.SpaceFree
END as [space_free]
,[a].SpaceUsed as [space_used]
,[a].[MaxSizeBytes] as [max_size_bytes]
,[a].[EffectiveMaxBytes] as [effective_max_bytes]
,ReclaimablePages
from a
)
select
[MountPoint]
,[DriveSize]
,[DriveFreeSpace]
,[VolumePercentUsed]
,[DatabaseID]
,[DatabaseName]
,[DatabaseSize]
,[FileGroupName]
,[LogicalFileName]
,[FileType]
,[FileSize]
,[SpaceFree]
,[SpaceUsed]
,[FilePercentUsed]
,[GrowAt]
,[MaxSize]
,[EffectiveFileMax]
,[UsedPercentOfEffectiveMax]
,[AvailableSpaceToUse]
,[PhysicalName]
,[ShrinkCmd]
,[AutoGrowth]
,[RecoveryModel]
,[RecoveryModelCmd]
,[LogReuseWait]
,[VLFCount]
--Other columns, not displayed, but useful for filtering/ordering:
--,[ReclaimableInTheFilegroup]
--,[drive_size]
--,[drive_free_bytes]
--,[db_size]
--,[file_size_bytes]
--,[space_free]
--,[space_used]
--,[max_size_bytes]
--,[effective_max_bytes]
--,[ReclaimablePages]
from b
WHERE 1=1
--AND MountPoint='G:\'
--AND DatabaseName LIKE 'AdventureWor%'
--AND DatabaseName not in ('master','model','tempdb','msdb')
--AND RecoveryModel = 1 --1=Full
--AND FileGroupName='PartitionFG9'
ORDER BY [ReclaimableInTheFilegroup] DESC, [DatabaseID] ASC, FileGroupName ASC
DROP TABLE #TMPSPACEUSED
DROP TABLE #DBs
DROP TABLE #FileGroup
DROP TABLE #LogInfo
“Filegroup Aware”
One of the things I’m most proud of with this script is actually easy to miss… the sort order. I’m not an expert on filegroups, but based on my understanding of SQL’s proportional file-fill algorithm, you want to try to keep the files in a filegroup as close as possible to the same size. As such, the script works as follows:
- It finds the file in each filegroup that’s using the most space
- The script attempts to shrink all files to that size
- No files are grown (that would defeat the purpose of freeing-up space)
Based on how much the script estimates can be reclaimed in the whole filegroup, the results are sorted (by filegroup), with the biggest space-savers on top. If you aren’t using explicit filegroups, don’t worry- the files with the most free space will float to the top.
Below is a picture from my slide-deck to help you visualize the calculation:
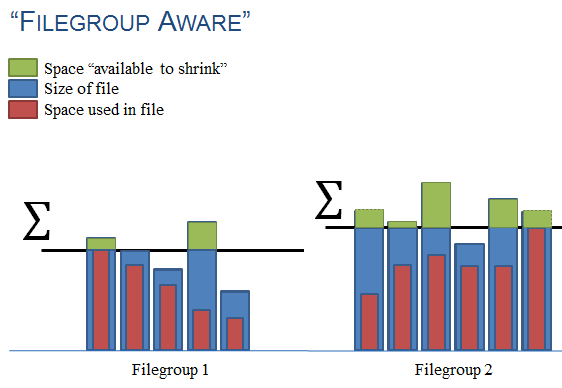
The green space is summed for the filegroup, and the filegroup with the most “free space” (calculated as described above) will be on top. All the files in a filegroup will sort together.
Ratio Bar
The last thing I wanted to point out is visual ratio bar:

It’s a normalization of a ratio, like a percentage, but with a resolution of 10 instead of 100. Having 100 characters resulted in too much scrolling, so I opted for just 10. I tried to find a word for this, but had no success. There’s a word for a ratio normalized to 1,000 (permillage) and one for 10,000 (permyriad), but I found nothing for 10. I wanted to call it a perdecage, but Google/Bing don’t seem to agree with me that it’s a real word.
As with any normalization, I wanted to point out that, while useful, it can be misleading. A file with 1MB free of 10 MB will look the same as a file with 100GB out of 1 TB. It’s not really a problem, but an observation.
For anybody wondering how I did it, here’s the magic line:
nchar(9621)+replicate(nchar(9608),floor((100-FilePercentFree)/10))+replicate(nchar(9601),ceiling(FilePercentFree/10))+nchar(9615)
For reference, the Unicode characters are as follows:
- nchar(9621): “▕”
- nchar(9608): “█”
- nchar(9601): “▁”
- nchar(9615): “▏”
So we have vertical bars on either end, and 10 characters between.. each either a full bar, or a “bottom 1/8 of a bar”, depending on the ratio.
Comparability with SQL 2008/2008 R2
There are two changes needed for the script to run in versions prior to 2012
- Wrapper function- you can’t use correlated parameters for DMFs like sys.dm_io_virtual_file_stats prior to 2012. The workaround is to create a user-defined wrapper function for it.
- dbcc loginfo- A new column was added to its output in 2012, [RecoveryUnitId]. The definition of the temp table in the script, #LogInfo, must be modified to remove that column if running it pre-2012.
These changes can be found in the second script below.
The full script can be found here: SpaceUsage.txt.
And a SQL 2008 version: SpaceUsage2008.txt.
Please let me know if you found this script useful or if you have any suggestions to improve it.
LLAP,
Ryan
A few sources I’d like to cite for contributing ideas:
- http://www.mssqltips.com/sqlservertip/1510/script-to-determine-free-space-to-support-shrinking-sql-server-database-files
- http://www.mssqltips.com/sqlservertip/1629/determine-free-space-consumed-space-and-total-space-allocated-for-sql-server-databases
As always, please note the waive of liability published on the About page.
The text of this entire blog site (including all scripts) is under the copyright of Ryan Snee. You are free to reproduce it, as outlined by the Creative Commons Attribution-ShareAlike 3.0 Unported License.